
Explorons l’analyse de la donnée. Partie 1 : installation des outils
Introduction
Cette article débute une série d’articles concernant l’analyse de la donnée. La démarche est exploratoire, les résultats seront présentés petit à petit dans de futurs articles.
Cela impose quelques explications. Quand on parle d’analyse de la donnée, de quoi s’agit t’il ?
Pour y mettre un visage cela se traduit par un métier très en vogue, le métier de data scientist. Sa définition est selon wikipedia :
Le premier objectif du « data scientist » est de produire des méthodes (automatisées, autant que possible) de tri et d’analyse de données de masse et de sources plus ou moins complexes ou disjointes de données, afin d’en extraire des informations utiles ou potentiellement utiles.
Pour cela, le « scientifique des données » s’appuie sur la fouille de données, les statistiques, le traitement du signal, diverses méthodes de référencement, apprentissage automatique et lavisualisation de données. Il s’intéresse donc à la classification, au nettoyage, à l’exploration, à l’analyse et à la protection de bases de données plus ou moins interopérables.
Un ordinateur, un soupçon d’informatique et un bloc note
 Deux langages informatiques sont prépondérants pour faire de l’analyse de données : le langage Python et un dérivé, le langage R. J’utiliserai le langage Python qui peut être utilisé pour beaucoup d’autres usages.
Deux langages informatiques sont prépondérants pour faire de l’analyse de données : le langage Python et un dérivé, le langage R. J’utiliserai le langage Python qui peut être utilisé pour beaucoup d’autres usages.
J’en profite pour passer un message : n’ayez pas peur des langages informatique, c’est accessible avec quelques bases simples … et à partir du moment où on peut copier des blocs de code tout fait pris à droite et gauche. Internet est une source inépuisable en ce qui concerne la programmation.
Avant d’automatiser, si possible, le traitement de cette donnée, il est nécessaire de l’explorer et de tester différentes méthodes et différents outils sur cette matière. Pour que cette exploration soit efficace, il faut un outil adapté, le bloc note du data scientist.
Un produit open source sort du lot : Jupyter qui est effectivement un bloc note en ligne permettant de mélanger des notes, du code informatique et le résultat généré par ce dernier. Le concept est vraiment génial ! Cela ressemble donc à quelque chose comme cela: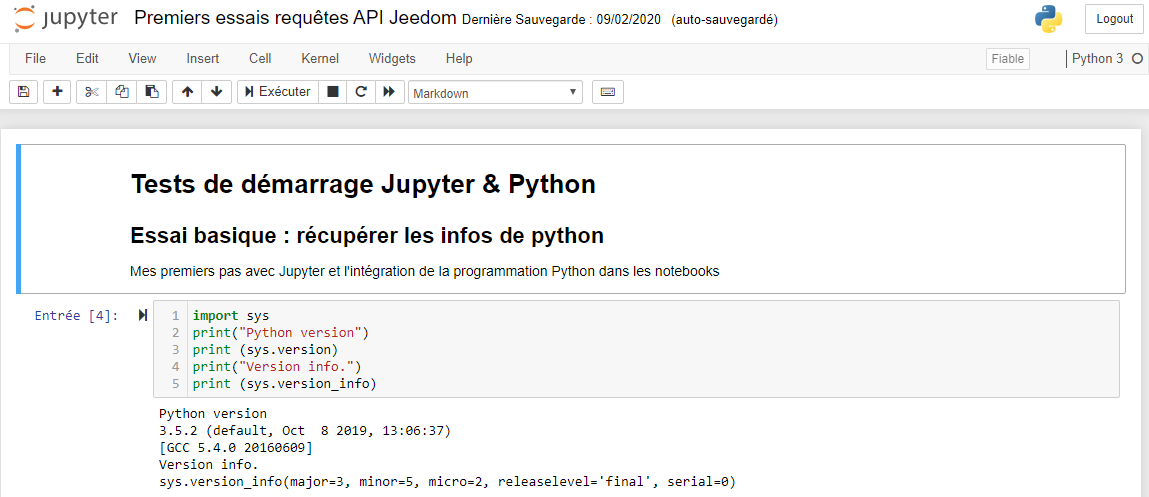
Autre avantage de Jupyter : l’exportation au format html des cahiers de notes que je vais pouvoir réimporter directement dans le blog pour générer un article. Trop facile !
Où et comment mettre en oeuvre Python et Jupyter
J’ai trois solutions à vous proposer, allant de la plus évidente à la plus complexe :
1. Créer un compte sur l’espace colab de google
Cela se passe là : https://colab.research.google.com/.
Créer un compte google si vous n’en avez pas déjà un, et cet espace infini et au delà est à vous sans autre manipulation !
En effet google fournit gratuitement un environnement de travail basé sur jupyter qui vous permet de réaliser ces expérimentations sans rien installer.
2. Installer le nécessaire sur votre PC habituel
Désolé je n’ai pas choisi cette solution, c’était trop simple 😉 . Mais vous avez de nombreux articles qui vous aideront à réaliser cette installation dont certains en français :
3. Installer sur un serveur linux
Jupyter est un service Web, on y accède avec un browser internet. Cela a donc du sens que ce soit hébergé sur un serveur. Par ailleurs en l’installant sur mon serveur linux, au plus proche des bases de données, je m’assure d’un traitement efficace.
Cela me permet aussi de vérifier que ce serveur a la puissance nécessaire pour traiter automatiquement ces données dans un temps raisonnable, une fois la période d’exploration passée.
Installation d’une machine virtuelle hébergeant Jupyter
Voici les étapes que j’ai passées pour installer Jupyter. Cette installation s’est faite dans une machine virtuelle séparée des autres fonctions du serveur, pour des raisons de sécurité, mais surtout pour être en mesure de pouvoir limiter la puissance CPU utilisée par Jupyter sur le serveur. Les traitements pourraient effectivement devenir lourds, mais cela ne doit pas impacter les autres fonctions du serveur.
L’OS de ce serveur est Ubuntu serveur en version 16.04 ( Xenial), version du noyau 4.4.0-174-generic. Le système de fichier est au format btrfs.
1. Création et configuration d’un container LXC
J’utilise la technologie LXC pour installer un équivalent de machine virtuelle linux. Cette technologie se base sur trois principes
- l’utilisation du même noyau linux que la machine hôte
- le chroot qui permet de séparer le système de fichier du container LXC de celui de la machine hôte
- Un namespace séparé isolant complètement les actions effectuées dans le container de la machine hôte et des autres containers
A l’utilisation, cela signifie qu’on a l’impression d’être sur une machine complètement séparée des autres, mais en gardant des performances identiques à la machine hôte.
Avant de créer ce nouveau container, je crée un subvolume btrfs qui me permettra de réaliser par la suite des snapshots (des sauvegardes flash) séparées de ce container
cd /var/lib/lxc btrfs subvolume create lxc-linuxai
Puis création du container
lxc-create -t download -n lxc-linuxai -- -d ubuntu -r xenial -a amd64
Modification de la configuration du container (paramétrage réseau, réduction des ressources de calcul et mémoire allouées à la machine)
cd lxc-linuxai nano config
******** Contenu fichier config ******** #Auto Start lxc.start.auto = 1 lxc.start.delay = 17 lxc.aa_profile = unconfined # Common configuration lxc.include = /usr/share/lxc/config/ubuntu.common.conf # Container specific configuration lxc.rootfs = /var/lib/lxc/lxc-linuxai/rootfs lxc.rootfs.backend = dir lxc.utsname = lxc-linuxai lxc.arch = amd64 # Network configuration local lxc.network.type = veth lxc.network.name = eth0 lxc.network.link = br0 lxc.network.flags = up #Hardware setup #lxc.cgroup.memory.limit_in_bytes = 2048M #lxc.cgroup.cpuset.cpus = 1 lxc.cgroup.cpu.shares = 200 # Network configuration Out lxc.network.type = veth lxc.network.name = eth1 lxc.network.link = out0 lxc.network.flags = up
Enfin on démarre ce container, on s’assure que la connectivité réseau est bien montée, puis on se connecte dans ce container pour effectuer sa configuration interne.
lxc-start lxc-linuxai lxc-ls --fancy lxc-execute lxc-linuxai -- /bin/bash
2. Configuration de la machine virtuelle
La connectivité réseau est essentielle, donc première étape, la configurer ou la vérifier
cd /etc/network vi interfaces
******** Contenu fichier interfaces ******** auto lo iface lo inet loopback auto eth0 iface eth0 inet static address 192.168.2.xx network 192.168.2.0 netmask 255.255.255.0 gateway 192.168.2.xx dns-nameservers 192.168.2.xx
Redémarrage de l’interface réseau pour mettre à jour la configuration. On peut alors réaliser une mise à jour des paquets avec apt-get puis installer et le démarrer le serveur ssh
ifdown eth0 ifup eth0 apt-get update apt-get upgrade apt-get install nano apt-get install openssh-server service ssh start
Il est à présent possible de se connecter en ssh directement à la machine virtuelle (utilisation du logiciel putty par exemple). L’ utilisateur/mot de passe par défaut est ubuntu/ubuntu.
3. Installation de Python et Jupyter
Par défaut ubuntu installe Python2, et l’utilise pour différents usages. Néanmoins cette version est ancienne, et certaines bibliothèques d’importance pour le traitement de la donnée ne seront plus maintenues pour python2. Installons donc Python3 puis Jupyter
apt-get install python3 python3-dev python3-pip python3 -m pip install --upgrade pip apt-get install ipython ipython-notebook pip install jupyter
Faisons en sorte que l’accès à Jupyter ne soit pas limité à la machine locale
jupyter notebook --ip='*' --allow-root
Jupyter peut être lancé automatiquement au démarrage de la machine si un service est programmé.
nano /lib/systemd/system/jupyter.service systemctl enable jupyter.service systemctl start jupyter.service
******** Contenu fichier jupyter.service ******** $ cat /usr/lib/systemd/system/jupyter.service [Unit] Description=Jupyter Notebook [Service] Type=simple PIDFile=/run/jupyter.pid # Step 1 and Step 2 details are here.. # ------------------------------------ ExecStart=/usr/local/bin/jupyter-notebook --config=/home/jupyter/.jupyter/jupyter_notebook_config.py User=ubuntu Group=ubuntu WorkingDirectory=/home/jupyter/ Restart=always RestartSec=10 #KillMode=mixed [Install] WantedBy=multi-user.target
4. Installation de librairies python3
L’une des forces du langage python est la disponibilité de multiples librairies offrant des fonctions avancées. A minima les librairies suivantes sont nécessaires car très largement utilisées dans le domaine de l’analyse de donnée :
- matplotlib : fonctions pour traçage de graphiques
- pandas : fonctions d’analyse de donnée de masse
Pour rappel,python2 et python3 sont installés, mais c’est bien python3 qui sera utilisé pour le traitement de la donnée. L’installation se fait donc avec la commande pip3 impérativement.
pip3 install matplotlib pip3 install pandas
5. Installation finie, accédons à Jupyter
On accède par défaut à Jupyter par cette adresse :
http://adresse.ip.machine.virtuelle:8888
Au premier accès, il est possible de fixer un mot de passe pour protéger son accès.



2 réponses
[…] développé le code sur Jupyter. L’installation sur serveur est expliquée ici. La programmation est en Python.Utilisation des librairies numpy, pandas, geopandas, […]
[…] développé le code sur Jupyter. L’installation sur serveur est expliquée ici. La programmation est en Python.Utilisation des librairies numpy, pandas, geopandas, […]